Inheritance, JPA Custom Queries, and Projection
Topics to be Covered¶
- JPA Query Methods:
- Declared Queries
- HQL Queries
- Native SQL Queries
- Projections
- Model Inheritance Representation
- Introduction to Eager Fetching and Lazy Loading
JPA Query Methods¶
Practical Scenario¶
Consider a situation where you need to retrieve products based on their category. Normally, you might define a query method like:
List<Product> findByCategoryId(Category category);
However, in real-world applications, the service layer might not always have access to the full Category object, but only a part of it, such as the category name. This necessitates the execution of two separate queries:
- Fetch the category by its name:
Category c = catRepo.findByName(name); - Fetch the products by the category object:
List<Product> products = productRepo.findByCategory(c);
While this approach works, it involves making two database calls, which is inefficient, especially in a high-scale application where performance is critical.
Optimized Query with Declared Queries¶
To address this inefficiency, JPA allows us to create a more optimized query method that directly uses the category name to fetch the products, eliminating the need for multiple database calls:
List<Product> findAllByCategory_TitleLike(String categoryTitleLike);
In this method, the underscore (_) allows us to navigate through the related entities, directly accessing the title field of the Category entity associated with the Product entity.
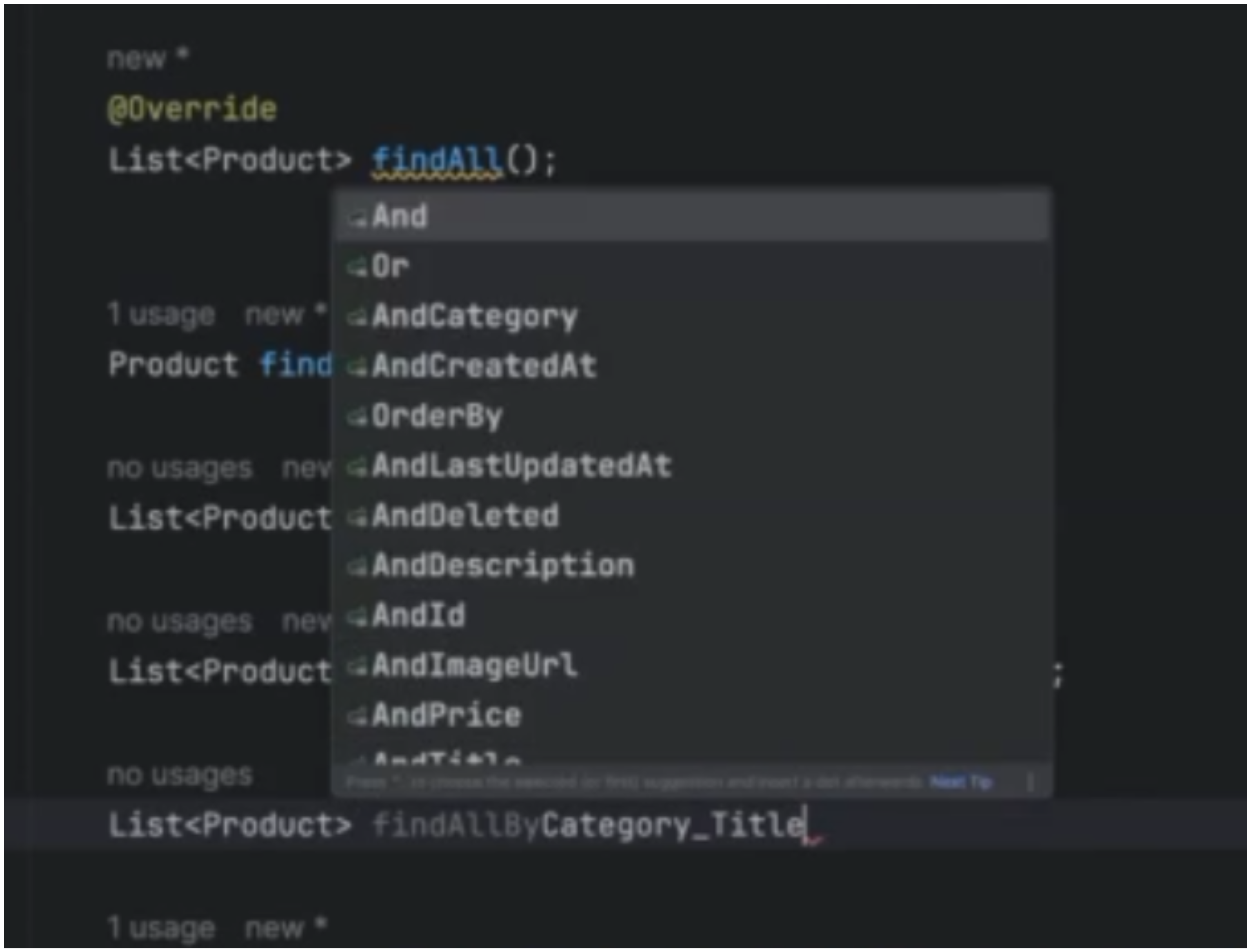
Limitations of Declared Queries¶
Despite the convenience, declared queries have some notable limitations:
- Lack of Explicit Query Visibility: The actual SQL query being generated and executed by the JPA provider is not visible to the developer. This can make debugging and optimization more challenging.
- Fetching All Columns by Default: Declared queries often retrieve all columns of the entity, which can lead to unnecessary data transfer, consuming more network bandwidth than necessary.
To overcome these limitations, more advanced querying techniques such as HQL (Hibernate Query Language) and Native SQL Queries are used.
Hibernate Queries (HQL)¶
Introduction to HQL¶
Hibernate Query Language (HQL) is a powerful querying language that is similar to SQL but integrates object-oriented principles. Unlike SQL, which operates directly on database tables and columns, HQL works with persistent objects and their properties, making it database-agnostic.
The Need for HQL¶
Consider a native SQL query like the following:
SELECT * FROM products p WHERE p.id = :id AND p.title = :title;
This query is specific to a particular database dialect (e.g., MySQL). If the underlying database is changed (e.g., to PostgreSQL or Oracle), the query may not work or may need adjustments.
HQL abstracts these database-specific details, allowing the same query to work across multiple databases supported by Hibernate, without modification.
Writing HQL Queries¶
Here’s how you can write an HQL query to achieve the same result as the above SQL query:
@Query("SELECT p FROM Product p WHERE p.category.title = :title AND p.id = :productId")
Product getTheProductsWithParticularName(@Param("title") String title, @Param("productId") Long productId);
- @Query Annotation: Used to define the query directly within the repository interface.
- @Param Annotation: Maps method parameters to the query parameters.
In HQL, you are working with Java entities and their properties, rather than raw database tables and columns. This approach provides several benefits:
- Portability: The same HQL query works across different databases.
- Simplicity: HQL allows you to work at a higher level of abstraction, focusing on business entities rather than low-level database details.
- Safety: Since you are working with entities, Hibernate can validate the query at compile-time, reducing runtime errors.
Projections¶
The Challenge of Selective Data Retrieval¶
Often in database operations, especially in large applications, you might not need to retrieve entire entities from the database. Instead, you might be interested in only a few specific fields. For instance, you might need just the title and id of products rather than fetching the entire Product entity.
Enter Projections¶
Projections in JPA allow you to retrieve only the specific fields you need, instead of the entire entity. This selective data retrieval can significantly reduce the amount of data transferred over the network, improving performance.
Projections are typically defined using Java interfaces, which contain getter methods for the fields you want to retrieve.
Example of a Projection¶
Let’s consider a scenario where you want to retrieve the id, title, and description of products:
package dev.naman.productservicettsmorningdeb24.repositories.projections;
public interface ProductProjection {
Long getId();
String getTitle();
String getDescription();
}
Here’s how you would use this projection in a JPA query:
@Query("SELECT p.title AS title, p.id AS id FROM Product p WHERE p.category.id = :categoryId")
List<ProductProjection> getTitlesOfProductsOfGivenCategory(@Param("categoryId") String categoryId);
In this query, only the title and id fields are retrieved, which are mapped to the ProductProjection interface.
Key Considerations with Projections¶
- Flexibility: The projection interface does not need to match the database schema exactly. It can be a superset of the data you want to retrieve, allowing for more flexible data handling.
- Efficiency: By selecting only the necessary fields, you minimize the amount of data transferred, which is especially important in distributed systems.
Benefits of Using HQL and Projections¶
- Increased Query Visibility: You have a clear understanding of which fields are being fetched.
- Data Minimization: Retrieve only the data that is necessary, reducing the load on both the database and the network.
- Query Validation: Spring can still validate the HQL queries, ensuring they are syntactically correct and that all referenced entities and properties exist.
Native SQL Queries¶
When to Use Native SQL Queries¶
While HQL and JPA’s declared queries are powerful, there are scenarios where you need even more control over the query execution. This is where Native SQL Queries come in. Native SQL allows you to write raw SQL queries directly in your JPA repositories, giving you full control over the SQL syntax and execution.
Advantages of Native SQL Queries¶
- Fine-Grained Control: You can use all features of your database, including custom functions, complex joins, and optimizations like indexed queries.
- Optimization: Native SQL can be fine-tuned for performance, leveraging database-specific features that may not be available or as performant in HQL.
Drawbacks of Native SQL Queries¶
- Database Dependency: Native queries are tied to the specific SQL dialect of your database. This reduces the portability of your application.
- Lack of Validation: Since these queries are not managed by Hibernate, Spring cannot validate them at compile-time, increasing the risk of runtime errors.
Example of a Native SQL Query¶
Here’s how you might write a native SQL query to fetch products by id and title:
@Query(value = "SELECT * FROM products p WHERE p.id = :id AND p.title = :title", nativeQuery = true)
List<ProductProjection> doSomething(@Param("id") String id, @Param("title") String title);
In this example:
- nativeQuery = true: Indicates that this is a native SQL query rather than an HQL query.
- The query directly interacts with the database, providing full control over the execution.
Representing Inheritance in Database Models¶
MVC Architecture Recap¶
In the Model-View-Controller (MVC) architecture, models represent the data and the business logic of the application. These models often correspond directly to database tables. When dealing with complex data structures, it’s common to encounter inheritance, where a base class has one or more derived classes.
Understanding Parent-Child Relationships¶
In a parent-child relationship (is-A relationship), a child class inherits the properties and behaviors of its parent class. In database design, this relationship must be carefully mapped to avoid redundancy and ensure efficient data retrieval.
Example Scenario: User, Mentor, and Mentee¶
Consider a system where you have a User class
, which is a base class, and two child classes: Mentor and Mentee. The Mentor and Mentee classes inherit common attributes like id, password, and email from the User class.
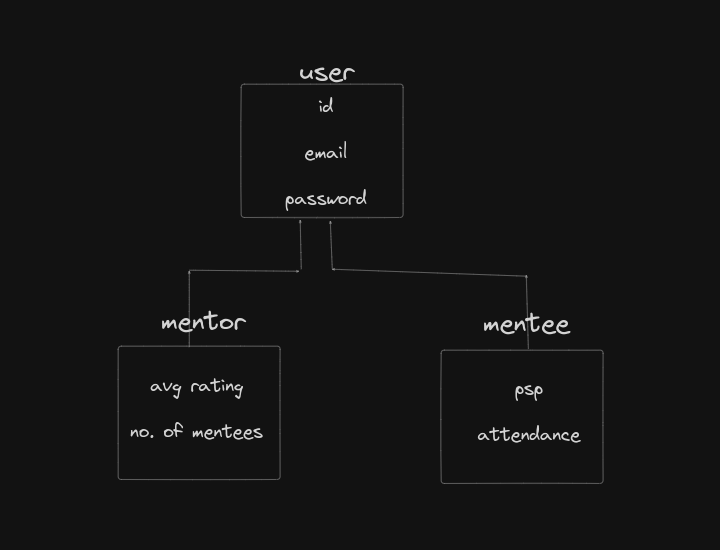
Strategies for Representing Inheritance¶
1. Table per Class Strategy¶
In this approach, each class, including the parent class, has its own table. Each table includes all the fields of the class it represents, including inherited fields from the parent.
- User Table:
| Id | Password | |
|---|---|---|
| ... | ... | ... |
- Mentor Table:
| Id | Password | Avg Rating | Count of Mentees | |
|---|---|---|---|---|
| ... | ... | ... | ... | ... |
- Mentee Table:
| Id | Password | PSP | Attendance | |
|---|---|---|---|---|
| ... | ... | ... | ... | ... |
Drawbacks:
- Redundant Data: Common fields (like
Id,Password,Email) are stored in multiple tables, leading to data redundancy. - Complex Queries: To retrieve all users or search by a common attribute (e.g.,
email), you must query all related tables, complicating the retrieval process.
2. Mapped Superclass Strategy¶
In this strategy, the parent class (User) does not have its own table. Instead, only the child classes have tables, each including its own fields plus the inherited fields from the parent class.
- Mentor Table:
| Id | Password | Avg Rating | Count of Mentees | |
|---|---|---|---|---|
| ... | ... | ... | ... | ... |
- Mentee Table:
| Id | Password | PSP | Attendance | |
|---|---|---|---|---|
| ... | ... | ... | ... | ... |
Drawbacks:
- Incomplete Parent Representation: There is no way to represent an instance of the parent class (
User) without also representing one of its child classes (MentororMentee). - Query Complexity: Queries that need to involve attributes from the parent class (e.g., finding a user by email) require checking multiple tables.
3. Single Table Strategy¶
All classes in the inheritance hierarchy (parent and child classes) are represented in a single table. This table includes columns for all attributes of the parent and child classes.
- User Table:
| Type | Id | Password | Avg Rating | Count of Mentees | PSP | Attendance | |
|---|---|---|---|---|---|---|---|
| ... | ... | ... | ... | ... | ... | ... | ... |
Drawbacks:
- Sparse Data: Many fields will have null values, as not all attributes apply to every instance (e.g., a
Menteewill not have values forAvg RatingandCount of Mentees). This leads to a sparse table, which is inefficient in terms of storage. - Storage Wastage: Storing large numbers of null values wastes space and can degrade performance.
4. Joined Table Strategy (Ideal Solution)¶
In this strategy, each class in the inheritance hierarchy has its own table, with the child tables having a foreign key reference to the parent table. This avoids data redundancy and ensures that data is only stored once.
- User Table:
| Id | Password | |
|---|---|---|
| ... | ... | ... |
- Mentor Table:
| User_Id | Avg Rating | Count of Mentees |
|---|---|---|
| ... | ... | ... |
- Mentee Table:
| User_Id | PSP | Attendance |
|---|---|---|
| ... | ... | ... |
Benefits:
- No Redundancy: Common fields are stored only once, in the parent table.
- Efficient Queries: Queries can easily join the parent and child tables to retrieve complete objects.
This strategy strikes a balance between data integrity, storage efficiency, and query performance.
